E3 공식 행사에서 AMD가 준비한 Next Horizon Event는 여전히 맛배기에 불과 했지만 RDNA 아키텍처와 관련된 상세 정보들이 일부 매체를 통해 전달되기 시작 했다.
오늘은 이 정보들을 모아 AMD가 만들어 낸 RDNA의 변화와 개선 점들을 정리해 볼까 한다.
참고로, RDNA는 이번에 발표된 NAVI 뿐만 아니라 향후 AMD에서 개발할 GPU의 근간이 되는 GPU 아키텍처로, 소니의 MS의 차세대 콘솔에 적용 됐을 뿐만 아니라 삼성에 공급할 모바일 GPU IP에도 사용될 계획이다.
RDNA, GCN에서 벗어나다
AMD는 오랫동안 GCN(Graphics Core Next) 아키텍처를 사용했다.
2012년 출시 된 라데온 HD 7730 부터 HD 8000 시리즈와 Rx 200 시리즈, 300, 400, 500 그리고 베가 시리즈까지 거의 8년여 동안 AMD를 대표하는 GPU 아키텍처 였다.
그 만큼 GCN에 대한 AMD의 애정은 남달랐지만 너무 오래 한 우물만 파온 탓에 전력 효율이나 성능 경쟁에서 매번 실패를 맛봐야 했고 소비자들은 AMD를 양치기 소년에 비유하며 플래그쉽에 대한 기대를 아예 접는 상황까지 가게 됐다.
이런 상황에서 GCN 만을 고집할 수 없던 AMD가 마침내 꺼내 든 새로운 GPU 아키텍처, RDNA는 GCN보다 업그레이드 된 성능과 전력 효율을 내세우며 소비자들에게 새로운 희망을 꿈꾸게 했는데 지금 부터 RDNA의 핵심들을 정리해 볼까 한다.
일단, AMD GPU의 CU에서 RDNA는 GCN과 다른 구조인 것이 확인 됐다.
AMD GPU의 근본 구조에서 16-Way SIMD 유닛은 GCN의 핵심이기도 했는데 이 SIMD 유닛이 32-Way로 2배 확장됐다. SIMD 유닛 자체도 4개씩 구성됐던 GCN과 달리 2개로 조정하고 스케줄러로 2개의 명령을 동시에 처리할 수 있도록 해 2개의 SIMD를 한 사이클에 처리하게 됐다.
이러한 변화는 AMD GPU에서 한번에 처리하는 쓰레드 단위인 Wavefront를 64개에서 32개로 줄이기 위한 것으로, 64개의 쓰레드 단위로 Wavefront를 처리하다 보면 16-Way SIMD 구조는 Wavefront 하나를 처리하기 위해 4 사이클을 회전하는 동안 3개의 SIMD 유닛은 아무 작업도 하지 않는 경우들이 생긴다.
이와 달리 RDNA는 32개 쓰레드 단위로 Wavefront를 사용하고 32-Way SIMD 두개가 동시에 작업을 처리할 수 있다 보니 한 사이클에 모든 작업을 완료할 수 있게 되어 작업 처리 시간이 빨라지는 것은 물론이고 쓰레드 단위가 적은 작업에서 보다 효율적으로 처리할 수 있게 됐다.
AMD는 이러한 구조를 강조하기 위해 GCN까지 사용하던 CU 대신 듀얼 CU라며 명칭을 변경했다.
RDNA는 GCN에서 사용 했던 64개 쓰레드 단위도 처리할 수 있다. 작업에 따라 이런 구조가 필요할 경우 CU 2개를 바인딩 하는 구조를 통해 처리하는 것이 가능하다. 단, 이 구조에서 SIMD 유닛은 저마다 다른 레지스터를 사용하기 때문에 64개씩 쓰레드를 묶은 Wavefront를 처리하기 위해 사이클은 한번 더 늘어날 수 밖에 없다고 한다.
참고로, AMD의 Wavefront 같은 엔비디아의 Warp는 오래 전 부터 쓰레드 단위를 32개로 사용해 왔다.
L1 캐쉬 추가, GPU 내부에도 DCC
GPU 내부에는 캐쉬 메모리가 있다.
CPU 처럼 복잡하고 다양한 작업을 처리하기 적합한 구조는 아니지만 갈수록 계산 작업이 복잡해 지면서 CPU와 비슷한 다층 캐쉬 구조가 일반화 됐고 GCN 또한 이러한 구조를 오래 유지해 왔다.
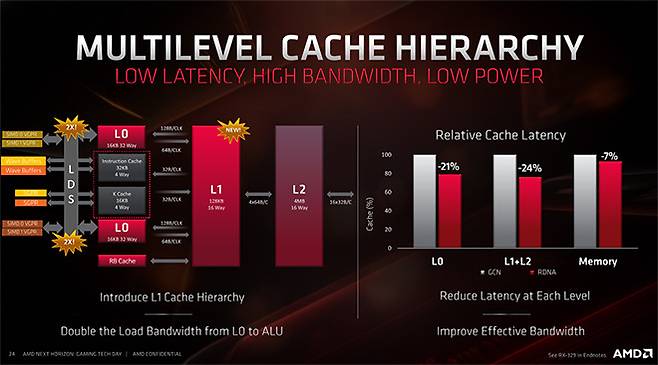
AMD는 RDNA에 보다 다층화된 캐쉬 구조를 적용했다.
각각의 CU마다 종속 됐던 L1 캐쉬를 L0 캐쉬로 대신하고 메모리와 직접 연결된 L2 캐쉬와 L0 캐쉬 사이에 L1 캐쉬를 적용했다.
L1 캐쉬는 CU 5개로 구성된 블럭 단위 마다 데이터를 공유하기 때문에 모든 CU가 L2 캐쉬로 연결 되는 GCN의 구조 보다 히트율이 높아 지연시간이 23% 개선 됐고 L0 캐쉬와 ALU 사이의 대역폭을 2배 개선해 21% 정도의 지연 시간 개선 효과를 가져온 것으로 소개됐다.
RDNA의 마지막 변화는 DCC다. Delta Color Compression의 약자인 DCC는 지금까지 메모리 컨트롤러와 메모리 버퍼 사이에만 적용했던 압축 기술로인데 이 기술을 GPU 내부 데이터 전송에도 활용한 것이 RDNA다.
대신, DCC를 처리하기 위해 메모리 컨트롤러에 연결 됐던 랜더 백 앤드를 CU 구조에 흡수시켜 쉐이더가 압축된 컬러 데이터를 읽거나 쓸 수 있게 했다. 이렇게 생성된 컬러 데이터는 랜더링 파이프라인 전반에 사용이 가능하기 때문에 내부적인 대역폭 절감에 크게 기여할 수 있게 된다.
참고로, L0+L1+L2로 다층화 된 캐쉬 구조는 엔비디아가 튜링 아키텍처에 이미 도입해 사용 중인 기술과 유사하다.
레이트레이싱, 쉐이더로 처리
RDNA에 레이트레이싱을 위한 전담 프로세서는 없는 것으로 확인됐다. 어느 정도 예상되던 그대로다.
하지만, 레이트레이싱에 대한 비전을 공개하며 전담 프로세서를 통한 하드웨어 가속과 클라우드 컴퓨팅를 이용한 완벽한 레이트레이싱 구현을 약속했다.
일단, 하드웨어 가속 기반의 레이트레이싱은 PS5와 프로젝트 스칼렛으로 발표된 차세대 콘솔 게임기에 우선 적용될 예정인데 상세한 설명은 없었지만 한정된 광석 추적 자원과 노이즈 제거 필터링 기술을 활용하는 엔비디아 RT 코어와 DXR(DirectX Ray Tracing)을 따라갔을 가능성이 높다.
어차피 PC 게임이라면 DXR을 사용할 수 밖에 없기 때문에 AMD도 DXR에 맞춰 광선 추적을 가속시킬 전담 프로세서를 탑재할 수 밖에
없다.
단, 쉐이더로 처리하는 현재의 레이트레이싱 방식은 GCN과 RDNA 모두 지원이 가능하지만 프로렌더와 라데온 레이로 구현하는 방식이라서 현재로써는 DXR 기반의 레이트레이싱은 사용이 불가능하다.
AMD가 개발한 SDK로 구현된 레이트레이싱만 지원이 가능한데 유니티 엔진에 적용 됐다는 소식 외엔 실제 게임 개발 소식은 전해지지 않고 있다.
미디어 가속, 8K 디코드는 H.264만
AMD 그래픽카드가 동영상 재생에 특별한 능력을 갖췄다고 인정 받은 것은 플루이드 모션이라는 프레임 보간 기술 때문이다.
TV 같이 자체적인 영상 보정 기능이 없는 모니터에서 24/30 프레임 영상을 60 프레임으로 보여주다 보니 그 동안 인정 받아온 색감과 더불어 동영상은 무조건 AMD라는 수식이 세워 졌고 지금도 많은 소비자들이 이런 생각에 부족한 게임 성능에도 AMD 라데온 시리즈를 선택해 왔다.
하지만, UHD 콘텐츠가 대세로 자리 잡으면서 색감이나 모션 만으로는 해결할 수 없는 문제들이 쌓이게 됐다.
그 중에서도 동영상 재생 문제는 치명타나 마찬가지 였는데 이제는 대표 스트리밍 서비스로 자리 잡은 유튜브에서 4K 영상이나 HDR 영상을 볼 때 마다 프레임 드롭이 생기다 보니 고화질 콘텐츠 재생에 한계가 지적되어 왔다.
이런 문제를 해결하기 위해 RDNA의 미디어 엔진은 VP9 코덱을 4K60까지 디코딩 할 수 있도록 개선됐다.
관련 내용을 자세히 소개한 매체가 없어 아직 정보가 부족하지만 APU에서 4K 콘텐츠에 대한 VP9 가속 문제를 해결한 바 있어 4K60까지는 SDR 뿐만 아니라 HDR 콘텐츠(VP9 Profile2)도 하이브리드가 아닌 순수 하드웨어 가속으로 처리할 수 있을 것으로 판단된다.
다만, 8K 콘텐츠는 H.264 코덱에만 30fps을 제한적으로 디코딩할 수 있고 유튜브의 경우 VP9을 기준으로 8K24 콘텐츠까지 디코드 할 수 있다고 설명하고 있어 2020년 이후 본격화 될 8K UHD 시대에 대응하기에는 여전히 부족한 점이 많다.
대표적인 상용 코덱인 H.265(HEVC)도 OBS에서 디코딩 하는 기준으로 8K24까지만 허용한다고 하니 사실 상 8K 콘텐츠를 감상하는 용도로는 활용이 어렵지 않을까 생각한다.
참고로, 엔비디아는 튜링 부터 VP9과 H.264(HEVC)에 대한 8K 디코딩을 하드웨어 가속으로 지원하고 있다.
라데온 RX 5700 XT와 RX 5700, 어떻게 될까?
RDNA가 적용된 첫 번째 GPU, 나비는 라데온 RX 5700 XT와 라데온 RX 5700으로 시장에 출시 된다. 두 제품은 엔비디아 지포스 RTX 2070과 RTX 2060을 타겟으로 더 높은 성능을 제공한다는 것이 AMD 측 주장이다.
AMD가 제시한 자료에는 꽤 많은 게임에서 경쟁 제품 보다 성능이 높은 것으로 정리 됐는데 이 결과가 100% 사실이라 해도 AMD와 엔비디아의 위치를 바꾸는 것은 쉽지 않은 현실이다.
왜 그런지는 몇 가지 시나리오만 분석해도 쉽게 답을 찾을 수 있다.
일단, 지포스 RTX 2060과 경쟁하겠다던 라데온 RX 5700은 높아진 성능 만큼 가격을 올려 성능과 가격 사이에서 게이머들을 고민하게 만들었다. 결국 저렴한 가격을 선택하거나 가격 만큼 높은 성능을 선택할 수도 있어 300달러 대 시장을 완전히 휘어잡기 어렵게 됐다.
라데온 RX 5700 XT는 지포스 RTX 2070 보다 저렴하지만 AMD가 제시한 벤치마크 자료에서도 모든 게임을 압도하지 못했다. 5% 내외로 근소한 차이가 많아 DXR 기반의 레이트레이싱을 RT코어로 가속하면서 DLSS로 프레임과 화질을 개선할 수 있는 지포스 RTX 2070 보다 결코 합리적인 선택이라 말하긴 어려운 상황이다.
8월로 예정된 엔비디아의 신제품 출시도 문제다.
AMD가 내놓은 라데온 RX 5700 XT와 라데온 RX 5700는 지포스 RTX 2070과 RTX 2060을 타겟으로 모든 것이 셋팅된 제품이라서 엔비디아가 가격만 조정해도 타격은 클 수 밖에 없다.
14nm/16nm 보다 2배나 비싼 7nm 공정의 GPU 생산 원가 때문에 가격 경쟁에 나서는 것도 어려운데 엔비디아가 예고한 "Something super is coming"이 소문 대로 신제품 출시로 이어진다면 AMD에겐 치명타가 될 가능성이 높다.